Software Reliability
Explain software reliability with respect to reliability measures and models.
What is software reliability?- It is the probability of failure-free software operation for a specified period of time in a specified environment.
- It is also an important factor that affects system reliability.
- Software reliability differs from hardware reliability in that it reflects the design perfection, rather than manufacturing perfection.
- It is one of the most important aspects of software quality.
Software reliability measurement:A software's reliability is measured in two waysA. Usage and reliability modeling
B. Application of reliability measurement
A. Usage and reliability modeling:- Reliability depends on the number of remaining faults that can cause a failure.
- There are two different types of models.
1. Usage specification
2. Reliability model
1. Usage specification- In this specification, it consists of a usage model and a usage profile that specifies the intended software usage.
- The test cases are run during the software test are generated from the usage specification.
- The specification may be constructed based on the data from real usage of similar systems or on application knowledge.
2. Reliability model- In this model, the sequence of failures is modeled as a stochastic process.
- This model specifies the failure behavior process.
- It also implies a need for an inference procedure to fit the curve to data.
- This model can be used to estimate or predict the reliability.
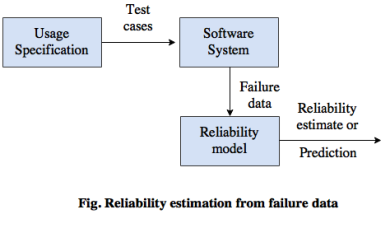
In the above diagram, failure intensity is an easier quantity to understand than reliability. In most cases, failure intensity can be derived from the reliability estimate, but mostly it is used as the parameter in the reliability model.
B. Application of reliability measurement:- The reliability measurement can be used for different purposes in software project management.
- It can be used for certification, that means to formally demonstrate system acceptability to obtain authorization to use the system operationally.
- The certification object can be either a complete product or in a component library.
- The certification can be used for internal development purposes such as controlling the test process etc.
- Reliability predictions can be used for planning purposes. The prediction can be used to judge how long time is remaining until the required reliability requirement is met.
- Predictions and estimations can both be used for reliability allocation purposes.
Software reliability models:Different Software reliability models are:
1. Time between failure models
2. Failure count models
3. Fault seeding models
4. Input domain-based models
1. Time between failure models- This model concentrates on, as the name indicates, modeling the times between occurred failures.
- The first developed time between failure model was the Jelinski-Moranda model from 1972, where it is assumed that the times between failures are independently exponentially distributed.
- The Jelinski-Moranda model is presented some more detail, since it is an intuitive and illustrative model.
2. Failure count models- This model is based on the number of failures that occur in different time intervals.
- The number of failures that occur is, with this type of model.
- The Goel and Okomoto model can be seen as the basic failure count model and as with the Jelinski-Moranda model, a number of variants of the model have been proposed.
3. Fault seeding models- This model is mostly used to estimate the total number of faults in the program.
- This model introduces a number of representative failures in the program.
- If the seeded faults are representative that is they are equally failure prone as the real faults, the number of real faults can be estimated by a simple reasoning.
4. Input domain-based models- In this model, the input domain is divided into a set of equivalent classes and then the software can be tested with a small number of test cases from each class.
- An example of an input domain-based model is the Nelson model.
Some of the other Software Reliability Models are:I. Reliability Growth Model- This model describes how the system reliability changes over the time during the testing process.
- As failures are discovered while testing the system, the faults causing these failures are repaired so as to improve the software reliability during the process of testing and debugging.
- To predict the reliability, the conceptual reliability growth model is translated into a mathematical model.
II. Equal Step Functional Model- This model describes the concept of reliability growth that explains the reliability goes on increasing each time a fault is discovered and repaired and then a new version of software is created.
- It assumes that the software repairs are always correctly implemented so as to reduce the number of software faults and associated failures in each new version of the system.
III. Littlewood and Verrall’s Model (Random Step Function Model)- This model analyzes the problem by introducing a random element in the reliability growth improvement effected by the software repair. Therefore, each repair does not result in an equal reliability improvement, but varies on the basis of random permutation.
- It allows a negative growth when a software repair produces further errors, thus decreasing the reliability.
IV. Jelinski and Moranda Model- This model states that each time an error is repaired the reliability does not increase by a constant amount, rather the reliability growth of fixing of an error is proportional to the number of errors present in the system at that time.
V. Reliability Prediction Model- Testing is very expensive but important to achieve quality software. However, there is a need to stop testing as soon as possible and not over-test the system.
- Testing must be stopped when the required level of system reliability is achieved.
- This required level of reliability can be checked using reliability prediction model and if this predicts that the required level of reliability will never be achieved, then in this case, the manager must decide to rewrite the components of the software.



